At a high level, vector DBs are storage systems for unstructured data types. That’s broad. It also doesn’t seem like it would generate hype. Why do people care? One of the main use cases for vectors is to store embeddings that are the foundation of ML models. Particularly, LLMs. If it can power ChatGPT, it can surely power anything.
Pinecone is one of the leaders in the space. They’ve just raised a monster Series B and they’ve really set up developers for success in highlighting some of the many use cases for AI. How can I leverage this for my purposes?
 |
|---|
| These fellas just sold for $53M by Mark Zucc’s Meta |
Ever use the slack plugin for giphy? I feel like it never does anything close to what I want it to. I’ll build a better one with Pinecone. Shall we? We’ll get started with our setup in a jupyter notebook and do some basics. First, install your basics
$ pip install -U pandas pinecone-client sentence-transformers tqdm
Then, let’s set up our index in Pinecone. Note: you’ll be limited to a single index on Pinecone’s free setup. Kind of a bummer, but I only need one bullet index.
from IPython.display import HTML
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import pandas as pd
# Load dataset to a pandas dataframe
df = pd.read_csv(
"~/Downloads/TGIF-Release-master/data/tgif-v1.0.tsv",
delimiter="\t",
names=['url', 'description']
)
print(df.head())
import pinecone
# Connect to pinecone environment
pinecone.init(
api_key="NICETRY",
environment="WISEGUY"
)
index_name = 'gif-search'
# check if the gif-search exists
if index_name not in pinecone.list_indexes():
# create the index if it does not exist
pinecone.create_index(
index_name,
dimension=384,
metric="cosine"
)
# Connect to gif-search index we created
index = pinecone.Index(index_name)
Splendid, splendid. Now, it’s time to get our transformer, create embeddings and store them. With our data set transformed, we’ll then be able to query for recommended gifs based off of an input.
from sentence_transformers import SentenceTransformer
# Initialize retriever with SentenceTransformer model
retriever = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
retriever
from tqdm.auto import tqdm
# we will use batches of 64
batch_size = 64
for i in tqdm(range(0, len(df), batch_size)):
# find end of batch
i_end = min(i+batch_size, len(df))
# extract batch
batch = df.iloc[i:i_end]
# generate embeddings for batch
emb = retriever.encode(batch['description'].tolist()).tolist()
# get metadata
meta = batch.to_dict(orient='records')
# create IDs
ids = [f"{idx}" for idx in range(i, i_end)]
# add all to upsert list
to_upsert = list(zip(ids, emb, meta))
# upsert/insert these records to pinecone
_ = index.upsert(vectors=to_upsert)
# check that we have all vectors in index
index.describe_index_stats()
You may notice the above step takes quite a while to load and run. Why’s that? These models and data have massive amounts of data behind them. By offloading these embeddings to a DB, we’re able to not need to keep any of this in memory or perform any calculations off of raw DB values. By having a hyper optimized store, we’re in a better spot here with a vector DB.
In order to calculate what is the “most similar” / “recommended” gif, we’ll need to transform our queryinto an embedding and then calculate the cosine similarity within the N dimensional space of the existing vectors. The DB will return us this value based on a KNN (10) method and we’ll then display this value to the user.
def search_gif(query):
# Generate embeddings for the query
xq = retriever.encode(query).tolist()
# Compute cosine similarity between query and embeddings vectors and return top 10 URls
xc = index.query(xq, top_k=10,
include_metadata=True)
result = []
for context in xc['matches']:
url = context['metadata']['url']
result.append(url)
return result
def display_gif(urls):
figures = []
for url in urls:
figures.append(f'''
<figure style="margin: 5px !important;">
<img src="{url}" style="width: 120px; height: 90px" >
</figure>
''')
return HTML(data=f'''
<div style="display: flex; flex-flow: row wrap; text-align: center;">
{''.join(figures)}
</div>
''')
Let’s give it a go for a basic prompt. Techie on his laptop
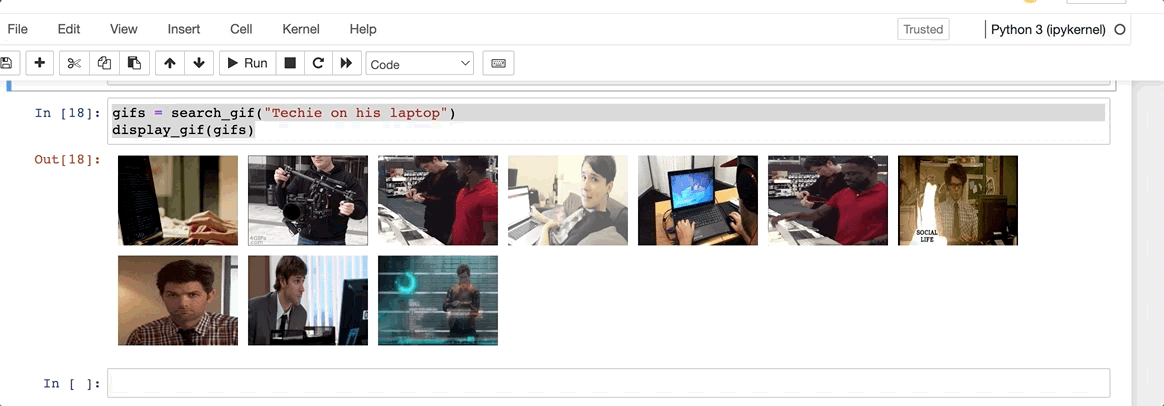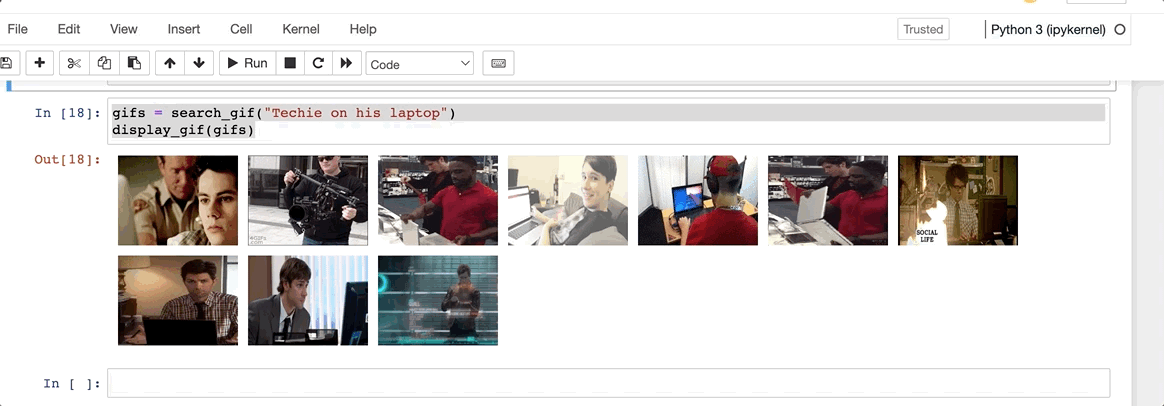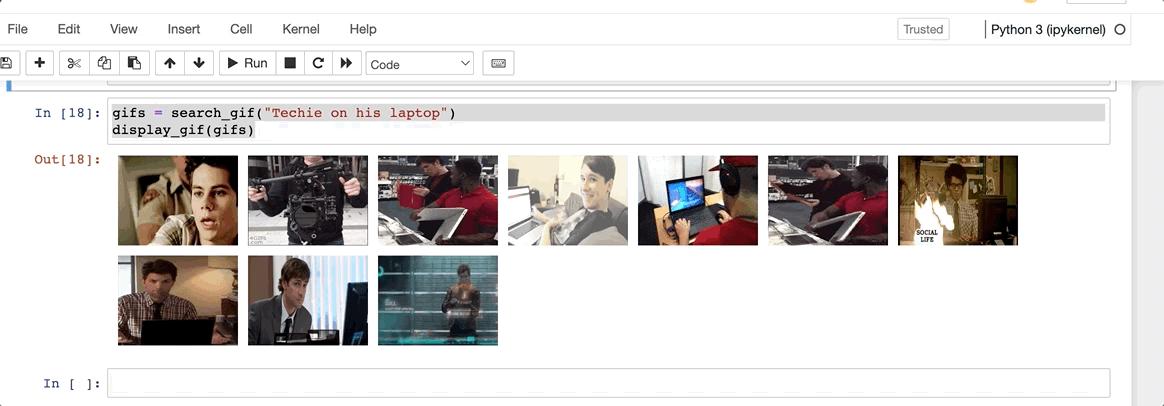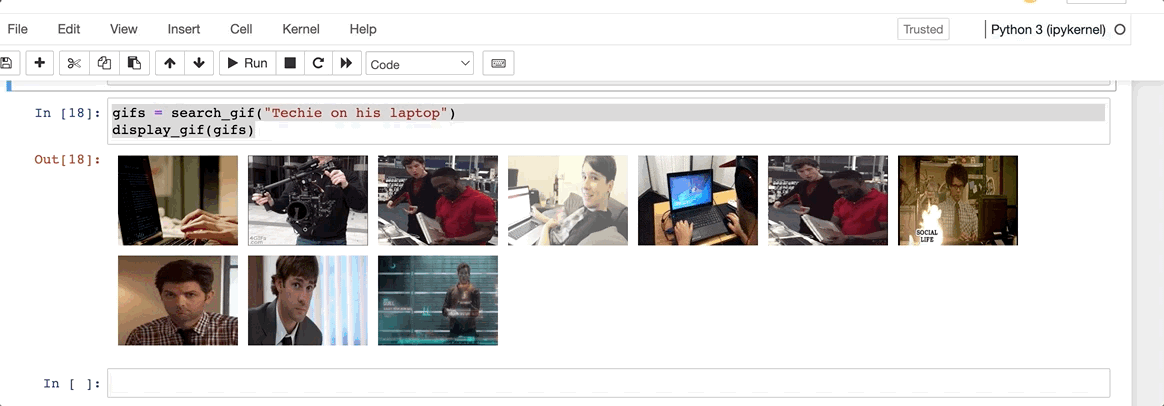
Not too bad. Everything seems to make perfect sense here. Not too techie, but I think that should do. How about something more specific?
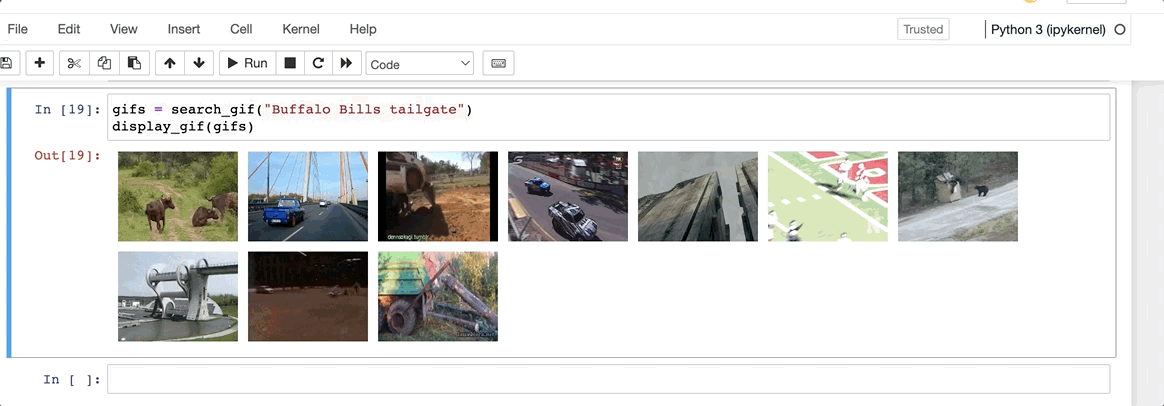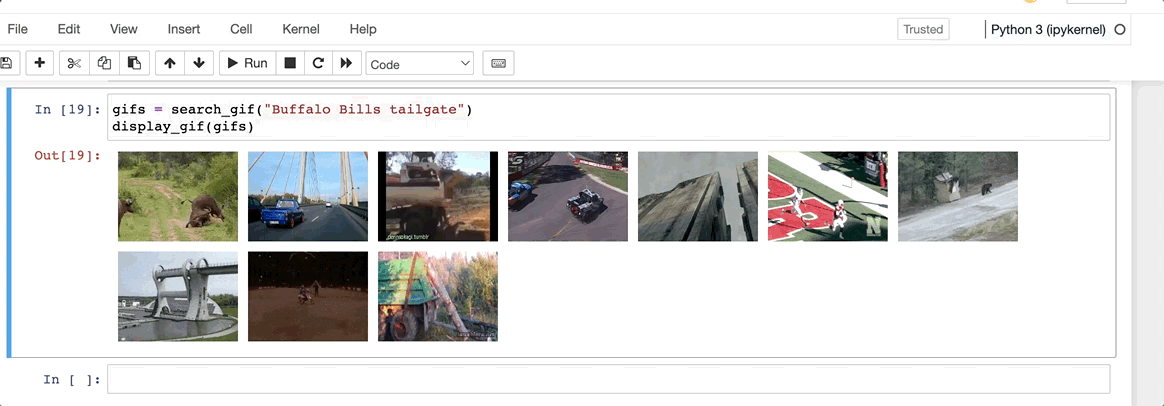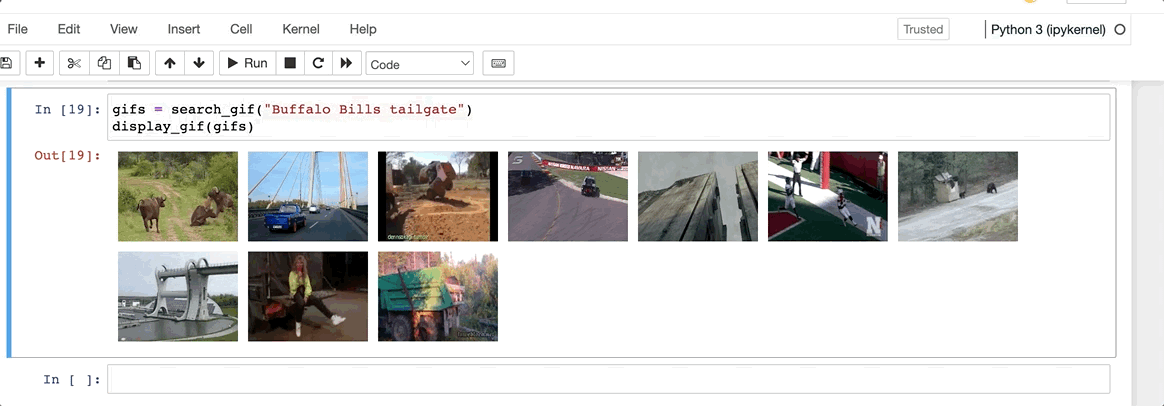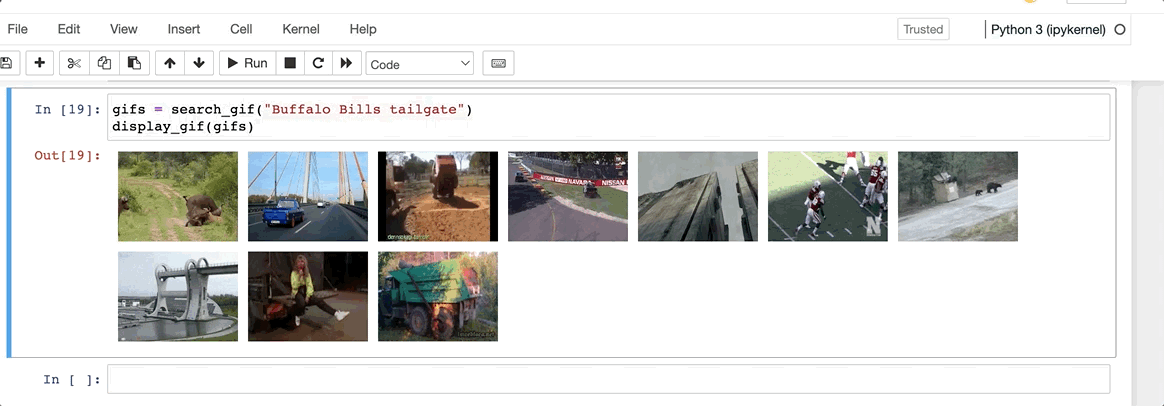
Wow, now that’s just awful. Looks like, despite their recent sale at a $262M Loss, Giphy still has some value to be found within every good slack troll’s plugin repetoire.
That being said, well done to the folksat Pinecone for making this so accessible.